At that point I realized that I don't have detailed knowledge about the decoding graph construction process and decided to take a closer look. One problem here is that the actual large vocabulary cascades are hard to observe directly. In my experience GraphViz requires exorbitant resources in terms of CPU time and memory even for graphs orders of magnitudes smaller than those used in LVCSR. Even if that wasn't a problem the full optimized HCLG WFST is in my humble opinion beyond the human abilities to comprehend(at least beyond my abilities). We can easily build a small-scale version of the graph however, and I think this is mostly OK because using small scale-models to design and test various constructs is a widely used and proven method in engineering and science. This blog entry is not meant to be a replacement for the famous hbka.pdf (a.k.a. The Holly Book of WFSTs) or the excellent Kaldi decoding-graph creation recipe by Dan Povey, to which this post can hopefully serve as a complement.
The setup
For our purposes we will be using very tiny grammars and lexicon. I decided to build the cascades using both unigram and bigram G in order to be able to observe the graphs evolution in slightly different settings. The "corpus" used to create the language models is given bellow (click to expand):
K. Cay K. ache Cay
The corresponding unigram model is:
\data\ ngram 1=5 \1-grams: -0.4259687 </s> -99 <s> -0.60206 Cay -0.60206 K. -0.9030899 ache \end\
Bigram model:
\data\ ngram 1=5 ngram 2=6 \1-grams: -0.4259687 </s> -99 <s> -0.30103 -0.60206 Cay -0.2730013 -0.60206 K. -0.2730013 -0.9030899 ache -0.09691 \2-grams: -0.60206 <s> Cay -0.30103 <s> K. -0.1760913 Cay </s> -0.4771213 K. Cay -0.4771213 K. ache -0.30103 ache </s> \end\
The lexicon contains just three words, two of which are homophones:
ache ey k Cay k ey K. k eyThe pronunciations have only two phonemes in total, because I wanted the graphs to be as simple as possible and the context-dependency transducer C, for example, becomes somewhat involved if more phones are used.
The script used for generating the graphs along with pre-rendered .pdf images can be found here. In order to run "mkgraphs.sh" you need to set a "KALDI_ROOT" environment variable to point to the root directory of a Kaldi installation.
Grammar transducer (G)
As in the aforementioned decoding graph recipe from Kaldi's documentation the steps my demo script is performing in order to produce a grammar FST are summarized by the following command(the OOV removal step is omitted since there are no out-of-vocabulary words in this demo):
cat lm.arpa | \
grep -v '<s> <s>' | \
grep -v '</s> <s>' | \
grep -v '</s> </s>' | \
arpa2fst - | \ (step 1)
fstprint | \
eps2disambig.pl |\ (step 2)
s2eps.pl | \ (step 3)
fstcompile --isymbols=words.txt \
--osymbols=words.txt \
--keep_isymbols=false --keep_osymbols=false | \
fstrmepsilon > G.fst (step 4)
Let's examine each step of this command and their effect on a bigram LM(unigram is analogous but simpler): First some "illegal" combination of the special language model start/end tokens are filtered out, because they can make the G FST non-determinizable. The result is then passed to arpa2fst which produces a (binary) G graph (the first slide below).
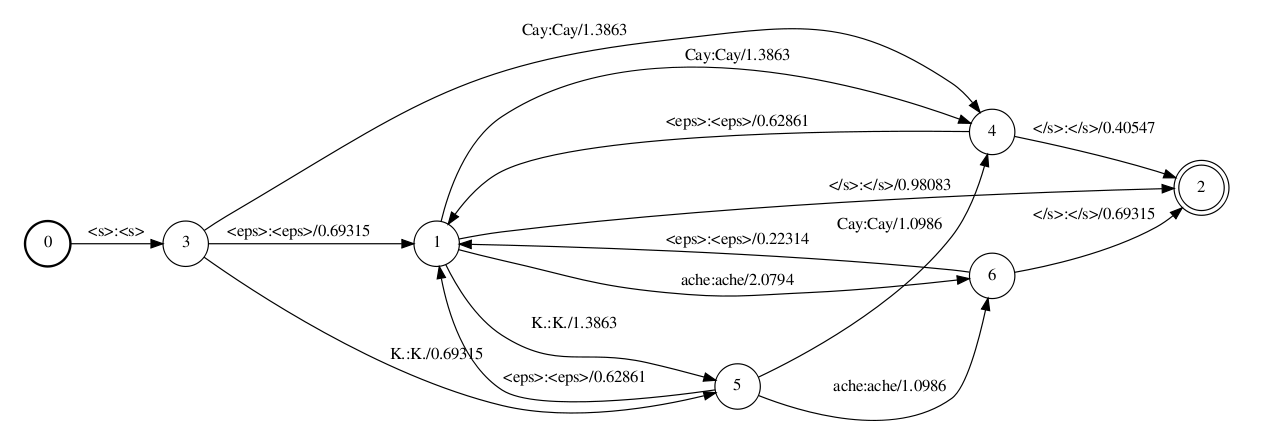
One thing to keep in mind here is that the weights of the FSTs are calculated by negating the natural logarithm of the probabilities, and the quantities given in ARPA file format are base 10 logarithms of probabilities. The WFST produced by arpa2fst is really straightforward but let's look little closer. There is a start node representing the start of an utterance (node 0), separate nodes for each of our "ache", "Cay", "K." vocabulary words (nodes 6, 4 and 5 respectively), a back-off node (1) and a final node(2) for the end of an utterance. Let's for the sake of the example trace a path through the graph corresponding to a bigram - say "<s> ache" bigram. Because there is no such bigram in our toy corpus we are forced to take the route through the back-off node, i.e. the arcs 0-3, 3-1, 1-6. The weight of the first arc is 0 (i.e. 1 when converted to probability), the weight of 3-1 arc is 0.69315, which corresponds to the back-off probability for "<s>" ($-ln (10^{-0.30103})$), and the weight 2.0794 of 1-6 arc corresponds to the unigram probability of "ache" ($-ln (10^{-0.9030899})$).
In step 2 of the above slides eps2disambig.pl script converts all epsilon input labels(these are used on the back-off arcs) to the special symbol "#0" needed to keep the graph determinizable. This symbol should be present in the word symbol table too.
Step 3 replaces the special language models "<s>" and "</s>" symbols with epsilons.
Step 4 is epsilon removal which simplifies the graph.
The word symbol table can be seen bellow:
<eps> 0 </s> 1 <s> 2 Cay 3 K. 4 ache 5 #0 6
Below the analogous graphs for the unigram LM are given:
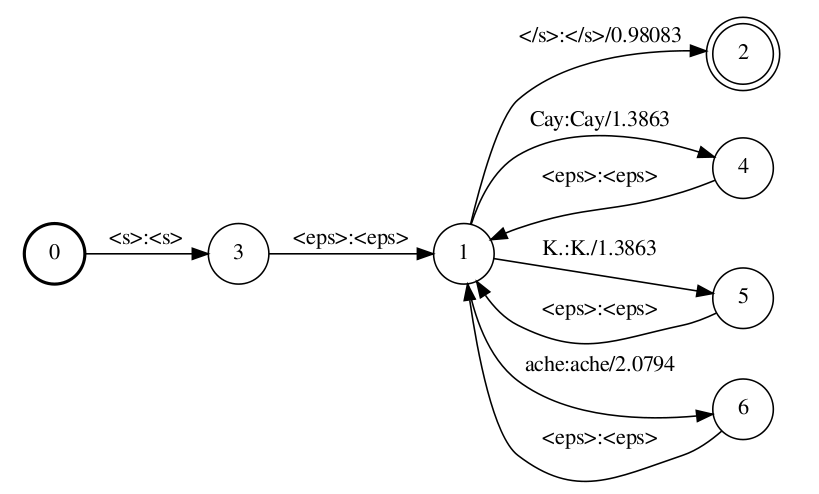
In what follows I will use cascades produced by composing with the unigram G only, because the graphs are smaller and the explanations of the following steps are not affected by the order of the grammar FST. If you want to have a look at the bigram versions you can use the .pdf files from the archive.
Lexicon FST (L)
The lexicon FST preparation used in Kaldi's recipes is fairly standard. For each homophone (in our case "Cay" and "K.") a distinct auxiliary symbol is added by the script add_lex_disambig.pl. So the lexicon now looks like:
ache ey k Cay k ey #1 K. k ey #2
The L FST is produced by the make_lexicon_fst.pl script. Which takes four parameters: the lexicon file with disambiguation symbols the probability of the optional silence phones the symbol used to represent the silence phones and the disambiguation symbol for silence.
make_lexicon_fst.pl lexicon_disambig.txt 0.5 sil '#'$ndisambig | \
fstcompile --isymbols=lexgraphs/phones_disambig.txt \
--osymbols=lmgraphs/words.txt \
--keep_isymbols=false --keep_osymbols=false |\
fstaddselfloops $phone_disambig_symbol $word_disambig_symbol | \
fstarcsort --sort_type=olabel \
> lexgraphs/L_disambig.fst
The resulting graphs can be seen on the slides below: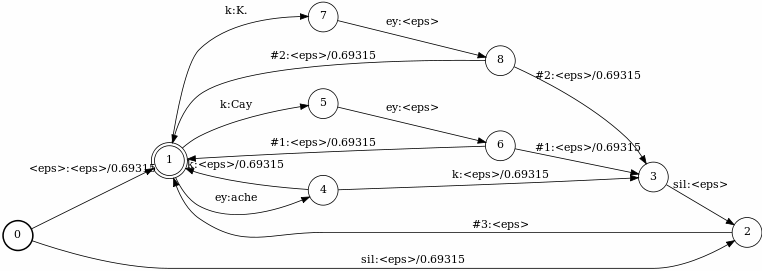
The graph on the first slide is the graph created by make_lexicon_fst.pl script. It adds optional silence (followed by the special silence disambiguation symbol #3) at the beginning of the sentence and also after lexicon word. On the second slide the special #0 self-loop can be seen, which is needed to pass the special symbol/word from G when it's composed with L.
The phone symbol table with disambiguation symbols is:
<eps> 0 ey 15 k 22 sil 42 #0 43 #1 44 #2 45 #3 46There are gaps in the IDs, because I am using a real acoustic model when building the H transducer (see below), so I wanted the phone IDs to match those from this acoustic model.
L*G composition
The commands implementing the composition are:
fsttablecompose L_disambig.fst G.fst |\ fstdeterminizestar --use-log=true | \ fstminimizeencoded > LG.fstThe commands used implement slightly different versions of the standard FST algorithms.
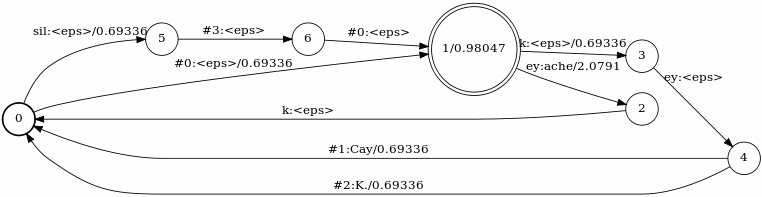
Context-dependency transducer (C)
The C graph is normally not created explicitly in Kaldi. Instead the fstcomposecontext tool is used to create the graph on-demand when composing with LG. Here, however we will show an explicitly created C graph for didactic purposes.
fstmakecontextfst \ --read-disambig-syms=disambig_phones.list \ --write-disambig-syms=disambig_ilabels.list \ $phones $subseq_sym ilabels |\ fstarcsort --sort_type=olabel > C.fst
The context dependency related graphs are given below:
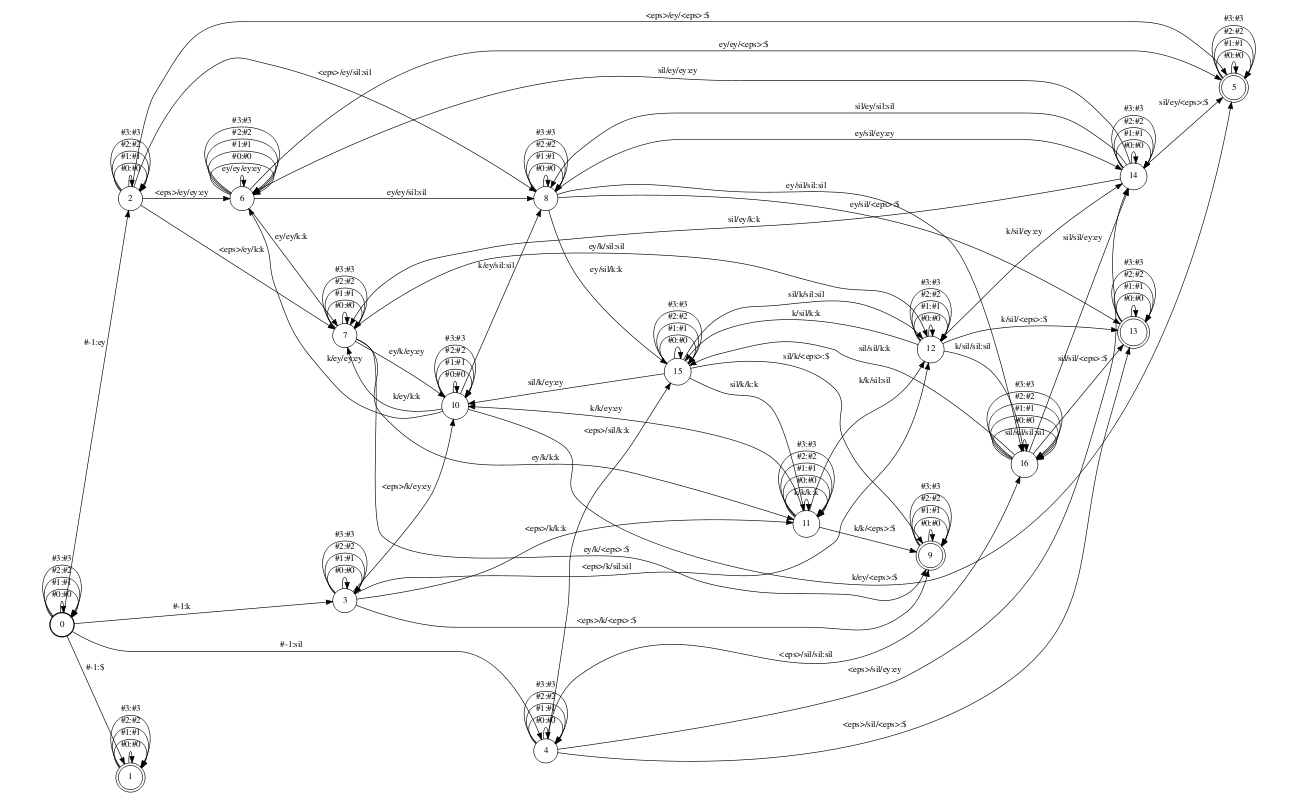
The first slide shows the C transducer, created by the command above. Each state has self-loops for all auxiliary symbols introduced in L. The input symbols of the C graph are triphone IDs, which are specified by using a Kaldi-specific data structure called ilabel_info(frankly clabel_info would have been more intuitive name for me, but perhaps there is reason it's called that way). Basically this is an array of arrays, where the the indices of the first dimension are the triphone IDs and the individual entries of the nested arrays are the IDs of the context-independent phones, which constitute the context window for the particular triphone. For example if there are triphone "a/b/c"(i.e. central phone "b" with left context "a" and right context "c") with id "10" the eleventh entry in the ilabel_info will be an array containing the context-independent ID's of the phones "a", "b" and "c". As explained in Kaldi's documentation for context independent phones like "sil" there is a single ID in the respective ilabel_info entry. Also for convenience the IDs of the special "#X" symbols are negated, epsilon is represented by an empty array, and "#-1"(see below) with array containing a single entry with value 0. There are couple of special symbols used in the graph. The "#-1" symbol is used as input symbol at the outgoing arcs of the start (0) node. In the standard recipe described in the Mohri et al. paper mentioned above uses epsilon at this place, but the Kaldi's docs say this would have lead to non-determinizable graphs if there are words with empty pronunciations in the lexicon. The second special symbol is "$\$$", which is used as output symbol for the inbound arcs of the final states. It is beneficial if C is made output-deterministic, because this leads to more efficient composition with LG. So in order to achieve this output determinism, the output(context-independent) symbols appear ahead (by N-P-1 positions in general) in respect to the input(context-dependent) symbols. So we "run out" of output symbols when we still have (N-P-1), or 1 in the most common triphone case, input symbols to flush. This is exactly the purpose of the "$\$$" - in effect it is sort of a placeholder to be used as output symbol at the arcs entering the final(end-of-utterance) state of C. We could use epsilon instead "$\$$" but this would have lead to inefficient composition because dead-end paths would have been explored for each triphone, not at the end of an utterance.
The additional "$\$$" symbols however should be accounted for ("consumed") in some way when C is composed with LG. The Kaldi's tool fstaddsubsequentialloop links a special new final state with "$\$:\epsilon$" self-loop to each final state in LG as you can see on the second slide. The self-loops are added for convenience because there are in general (N-P-1) "$\$$"-s to be consumed.
The third slide shows a transducer that can be composed with CLG in order to optimize the cascade. It does this by mapping all triphones, corresponding to the same HMM model to the triphone ID of a randomly chosen member of such set. For example it is not surprising that all instances of "sil" in all possible triphone context are mapped to the same triphone ID, because "sil" are context-independent and are represented by the same HMM model. Another such example is "<eps>/ey/<eps>:ey/ey/<eps>", i.e. "ey" with left context "ey" and no right context(end of utterance) is mapped to "ey" with both left and right context equal to "<eps>"(effectively meaning an utterance with a single "ey" phone). To see why this is so you can use Kaldi's draw-tree tool, which will show you that the PDFs in the HMMs for "<eps>/ey/<eps>" and "ey/ey/<eps>" are the same.
CLG cascade
The first slide below show the unoptimized version of (unigram) CLG, and the second the graph with physical-to-logical triphone FST(see above) composed from the left.

As a result of the physical-to-logical mapping, the states in the unigram CLG cascade were reduced from 24 to 17 and the arcs from 38 to 26.
H transducer
The H graph maps from transition-ids to context-dependent phones. A transition ID uniquely identifies a phone, PDF a node and an arc within a context-dependent phone. H transducers in fact look very similar to L transducers.
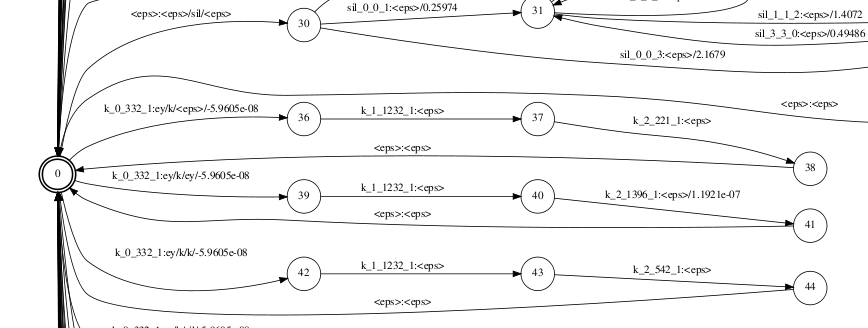
There is a start/end state with an arc going into a HMM state chain - one for each context dependent physical phone(note that there is not a chain with "ey/ey/<eps>" as an output symbol for example). Also there are self-loops for each auxiliary symbol used on C level(e.g. "#-1:#-1").
The input labels for this WFST are created with a simple tool I wrote previously. They encode the information contained withing a transition-id as four underscore-separated fields - phone, HMM state index withing the triphone, PDF ID and the index of outgoing arc from the node in the second field (in this order). For example "k_1_739_1" in this notation means that this is the transition-id associated with the state "1"(i.e. the second state) of the monophone "k" having PDF ID of 739(this is in general different for the different context-dependent versions of "k") and the outgoing arc from this HMM state, which has ID "1".
Note that the HMM-self loops are not included(thus the graph is actually called Ha) in this transducer and are only added after the whole HCLG cascade is composed.
HCLG cascade
The command used for creating the full cascade (without the HMM-level self-loops) is:
fsttablecompose Ha.fst CLG_reduced.fst | \ fstdeterminizestar --use-log=true | \ fstrmsymbols disambig_tstate.list | \ fstrmepslocal | fstminimizeencoded \ > HCLGa.fsti.e. the Ha and CLG(with physical-logical mapping applied) transducers are composed, determinized, the auxiliary symbols are replaced with epsilons(after all composition/determinization steps finished they are not needed anymore) and minimized.

The input labels are again in the format described above and are produced by fstmaketidsyms.
The graph from the second slide is created using:
add-self-loops --self-loop-scale=0.1 \
--reorder=true $model < HCLGa.fst > HCLG.fst
It adds self-loops adjusting their probability using the "self-loop-scale" parameter(see Kaldi's documentation) and also reorders the transition. This reordering makes decoding faster by avoiding calculating the same acoustic score two times(in typical Bakis left-to-right topologies) for each feature frame.And basically that's all. Happy decoding!
Hi,
i am miky.
have you convert HTK acoustic model to kaldi context dependency model?
This info is invaluable. Using the kaldi wiki is great too, but this is very condensed and quick to follow.
Nice Tutorial. It was very helpful. Keep posting!!
Very clear and helpful tutorial. Many thanks!
Hi, this is a very nice stuff!
BTW, I wonder if it's a typo in words.txt, i.e. word symbol table, I think sentence_start and sentence_end should not be there, as I observed in Kaldi experiments.
Thanks for valuable posting. It helped me a lot!
It seems grep -v '/s s' should be corrected to grep -v 's /s'. Is it right?
In the part when you create Context-dependency transducer (C) file, where do you get
disambig_ilabels.list?
I get an error
"fstmakecontextfst: ../fstext/context-fst-inl.h:114: [with Arc = fst::ArcTpl >; LabelT = int; fst::ContextFstImpl::Label = int]: Assertion `disambig_syms_.count(phone_syms[i]) == 0' failed.
ERROR: FstHeader::Read: Bad FST header: standard input"
Thank you so much meant for ad an extremely terrific report! I recently found your blog post perfect for my best necessities. It contains terrific together with practical articles or blog posts. Stick to beneficial financial job!
Secure Rentals
The link to "Kaldi decoding-graph creation recipe" in this article is broken, and the new one (according to google) is http://kaldi-asr.org/doc2/graph_recipe_test.html
I love the clarity and thoroughness of this, and only wish that the official Kaldi documentation could have been written more like it.
The latest link to "Decoding-graph creation recipe (test time)" is http://kaldi-asr.org/doc/graph_recipe_test.html
I'm not seeing the graphs anymore; Vassil, can you please put them up again? they are probably the most informative part
Please upload the images, because now the are not available
http://www.danielpovey.com/files/blog/pictures/kaldi-decoding-graph/cascade/CLG-thumb.png
the image is not found.
Sorry guys, I don't receive notification when someone posts a comment..
The problem with the images should be fixed now. Please use the http:// URL to access the blog, because the https:// version won't load all the images. Also, you may want to use Chromium to access the blog, because I notice the navigation controls for the "slides" are not shown in Firefox.
This blog is readable from my mobile, but not desktop. The figures are not visible even in mobile.
Hi Vassil, this post is still very useful today and could I get your permission to translate it into Chinese?
@chaoyang: Sure, please do!
the figure is not visible.
what should id do??
The Chinese translation is here
http://placebokkk.github.io/kaldi/asr/2019/06/28/asr-hclg.html
Thanks
Looking at HCLG graph, I think last id 1 is incoming arc for state 1 in the transition "k_1_739_1".is it right?
Hi
thanks for your explanation.
I got a big help.
I try to make new graph with new LM and old AM, but result is not good.
So I am checking the reason.
Can I ask something?
1. using graphviz, which file format did you use? jpg, pdf etc.
when I make a graph, resolution is very low, I cant recognize.
2. when I using fstprint for checking fst, what should I do?
in case of G.fst, using fstprint --isymbols=phones.txt --osymbols=words.txt HCLG.fst
error happened.
I have a question about the third image of atransducer: Let's say i have as input have the sequence "ey" "ey" "ey",according to the transictions wouldnt this output be tranduced to "ache" "ache" "ache" which is wrong cause in the input sequence the second phoneme of the word ache is missing ? (It seems like the transitions according to this tranducer would be: 0-1 1-4 1-4 1-4